Reflections on Judea Pearl’s science of causal reasoning
Dr. Mark Freestone lecturing on the Alan Turing stage at CogX19.
Back in June I was lucky enough to attend (indeed, exhibit at) this year’s CogX Festival of AI and Emerging Technology in London. It’s a fantastic event stuffed full of fascinating presentations— I urge you to come next year if you can — but of all the great talks I saw and encounters I had, one in particular stood out enough to make me want to sit down and write a blog post about it.
The presentation in question was by Dr. Mark Freestone. Freestone is a Senior Lecturer in the Centre for Psychiatry at the Wolfson Institute for Preventive Medicine; he’s also an Alan Turing fellow. What he had to say chimed powerfully with the contents of a book I’d read just a few weeks before, and which for my money sits alongside Daniel Kahneman’s “Thinking, Fast and Slow” as one of the books of the decade.
This was Judea Pearl’s “The Book of Why” (co-written with Dana Mackenzie), which is about cause and effect in statistics. As a student of philosophy and psychology and a part-time data scientist I’ve spent a fair chunk of my intellectual life pondering these things, which is why I picked it up and read it in the first place. And what a revelation it proved to be.

A historical timeline info board about the importance of Judah Pearl and Bayesian networks in the history of AI, from the “AI: More than Human” exhibition at London’s Barbican Centre, August 2019
Statistics tells us an enormous amount about the world, and now — thanks to analytical techniques of various flavours (from logistical regression to neural nets)— we’re baking statistical analysis at scale into the extraordinary data structures we’ve been building since the invention of the micro-processor and, more recently, the Internet.
We’ve now, with our usual hubris (and usual slavish adherence to the dictates of marketing), decided to call this development artificial intelligence, despite the fact that it’s not really intelligence at all but is, rather, pattern recognition and statistical analysis.
I don’t mean to demean the achievements that have been made in these sectors. But when compared to the processes at work in human or animal brains, they are akin to those at the “automated function” end — object persistence or facial recognition in vision, for example. Closer, therefore, to sensory perception than to the abstract cortical processing and decision-making that we generally refer to as “intelligence” (unless you work in marketing).
As every statistician knows, you see, “correlation is not causation.” But as Pearl points out in “The Book of Why”:
“Unfortunately, statistics has fetishized this commonsense observation. It tells us that correlation is not causation, but it does not tell us what causation is…. Student [of statistics] are not allowed to say that X is the cause of Y — only that X & Y are “related” or “associated”.”
Even more than that, statisticians have maintained for decades that correlation was enough, that causation was either unfathomable or not required. So perhaps it’s no surprise that, as the crowning achievement of the discipline that has produced it, correlation is what the current crop of AI technology does, and does very well indeed.
This is fine if we want an AI to tell an image of a dog from an image of a cat; to recognise a face or a voice or a word or a cancer cell in the midst of healthy tissue; to calculate routes and identify cars and pedestrians; even to work at how to win at video games. Iterated pattern recognition of labelled data with backward propagation for error correction bolstered by a range of other techniques to simulate the contributions of human memory or the layering function of the mammalian visual cortex can handle all of this admirably. If you ally the techniques to more traditional AI techniques like decision trees and other higher order logics, you can start beating grandmasters at chess or Go and start building (or attempting to build) self-driving cars.
The trouble starts when we want to ask why something happened or predict what might happen if in systems as unconfined and messy as the untrammelled physical world rather than in closed and rule-bound environments such as a Go board or the neatly laid out traffic grid of the average mid-Western US town. Observational data sets of the kind used to train neural networks in pattern recognition do not contain the answers to these kinds of questions, you see (q.v. “correlation is not causation”). When it comes to causal or predictive questions (predictive in the sense of predicting the future, rather than predicting the likelihood of a classification), “data are profoundly dumb”.
In other words, in the realm of actual thinking, rather than the processing that our visual cortices perform on the patterns of light that play across our retinae, these processes do not replicate what is going on in our heads. We do not use correlation to work out what might happen next. It’s part of the toolkit we might deploy, but it isn’t by any stretch the core mechanic of how we think.
When it comes to figuring out causation, we instead use scenarios and counterfactuals. We use fictions, not facts (a point that appeals to the novelist in me, as you might well guess). These fictions have their basis in fact (well, most of the time), but even so they are built on relatively few immediate data points. They are instead largely constructed from multiple reconstituted examples from our experience — what we call “common sense”. They also inherently probabilistic — something they have in common with correlation. What they don’t share with correlation, however, is the ability “to predict the effects of an intervention without actually enacting it,” as Pearl puts it in his book.
Well, I hear you say, doesn’t AlphaGo do exactly that? And the answer is, no, it does not. AlphaGo enacts millions of virtual scenarios along multiple forking paths of action to produce highly complex statistical analyses of possible outcomes, which are then encoded into the weights of its deep neural nets. This is incredibly effective and even capable of producing previously unappreciated insight into Go’s game mechanic (AlphaGo’s now famous move 37 and, subsequently, Sedol’s move 78). And it may even be, in the broadest sense, akin to what Lee Sedol himself is doing when he’s playing Go. But it’s not what Lee Sedol is doing when he’s trying to work out what he should buy his daughter for her birthday.
When Lee Sedol does that, he is spinning up various counterfactual scenarios involving various versions of his daughter and himself, various gift options, and a whole range of family scenarios possibly stretching well into the future, scenarios that “reflect the very structure of [his] world model.” None of these scenarios will have happened in the past, and none of them will happen in the future, but he will make a choice dependent on whichever of them conforms most closely with his world model. And then, when he sees his daughter’s (and his wife’s) reaction to the gift, he’ll perhaps embellish his world model according to the difference between his prediction and the perceived reality, thus deploying a training set, not of AlphaGo’s millions of examples, but of just one.
What’s strange about this is that the empirical observation can never fully confirm or refute the counterfactual. And yet counterfactuals are the primary tools we have for guiding our journey through the world in a cybernetic fashion, and thus are “the building blocks of moral behaviour as well as scientific thought.”
Current AI does not benefit from this mode of human thought. The importance of Pearl’s work, as encapsulated in “The Book of Why”, is that over the last three decades he has developed a method, a “causal calculus”, to enable the “algorithmization of counterfactuals”, and thus make them available to use by thinking machines.
What is causal calculus? In essence, it’s a way of modelling the probability (P) of an event (L) happening if an action (X) takes place, while taking into account both mediating variables (so enabling the calculus to model of indirect as well as direct relationships between action and outcome) and influencing variables (so enabling the calculus to quantify and/or isolate other factors that may confuse, complexify or obscure the key relationship being interrogated much as the paragon of this form, the randomised control trial, seeks to do).
Pearl and his collaborators have developed a visual vernacular for mapping the causal relationships between these various elements for any given situation. These causal graphs in turn allows the construction of counterfactuals: how the mapped causal calculus if an influencing variable impinged on this node instead of that node, or if a mediating relationship should turn out to be reciprocal instead of just one way, for example. Once the pathways have been mapped, it then becomes possible to take data generated in one scenario and test its validity or plausibility in another, apparently comparable, scenario.
This is much more than a Bayesian prior, though priors play an important role in estimating the initial conditions for any given do-calculus, as Pearl terms his graphs. But the do-calculus itself goes far beyond Bayesian techniques in its power and implications as it compartmentalises and tracks conditions that comprise the system under study, rather than taken a global probability snapshot at a given stage and feeding it back into the evolving prediction calculation. (For a nice summary of the technique — and a second recommendation of the book — check out this Medium post by data scientist Ken Tsui).
As you’d expect, in “The Book of Why” Pearl gives plenty of good toy examples of the do-calculus; what’s particularly interesting about these is the way that even a very simple causal graphs with only five or six nodes can help unpick incredibly thorny issues like the demonstration of causal relationship between smoking and lung cancer, or the comparative impacts of nature and nuture on personality.
It’s in these test cases, too, that we are able to see the profound impact of this approach on the entire discipline of statistics. It means no less than:
“the mantra “Correlation does not imply causation” should give way to “Some correlations do imply causation.””
The do-calculus is the technique that allows us — or our computers — to interrogate situations and their counterfactuals to work out which correlations those are.

Dr. Freestone continues his lecture at CogX19, with an example of a full causal graph.
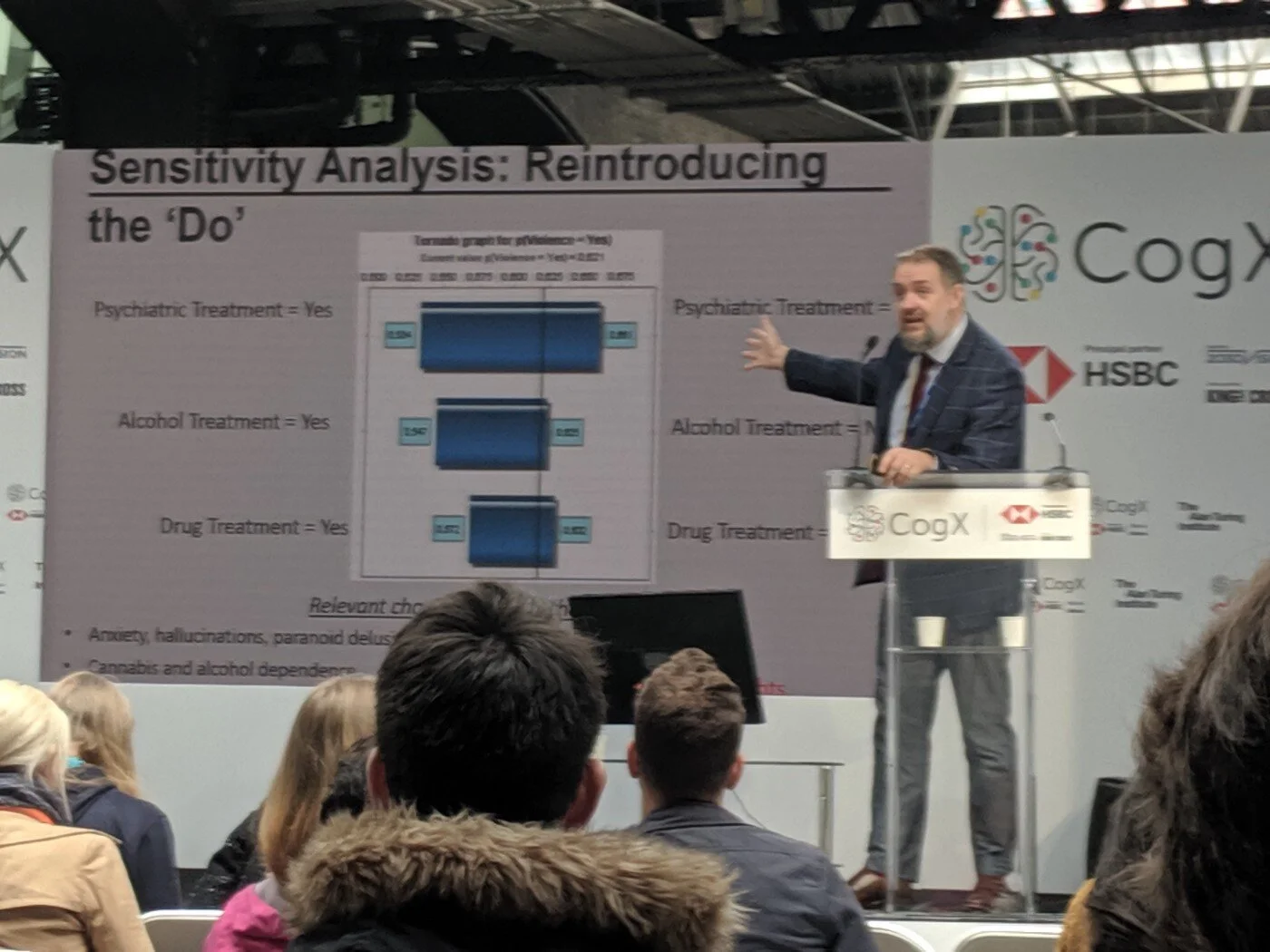
So now, I hope, it should be apparent why Mark Freestone’s talk at CogX 2019 excited me so much. It was the first example I’d come across since reading Pearl’s book of someone applying the do-calculus in the wild. As you can see from the photograph above, the causal graph of actions, outcomes, influences and mediators gets pretty crazy pretty fast when you’re trying to understand cause and effect in a situation as complex as the development of risk models for prediction and management of violence in mental health services (the focus of Freestone’s study).
The approach is also already beginning to make an impact on robotics. Start-up Realtime Robotics is making great progress on enabling interactive movement in machines by using counterfactual causal models, creating a specialised processor and scripting language (Indigolog) specifically to enable it. DeepMind has been mucking about in this area too, as you’d expect. Check out some of their research findings here.
I don’t pretend to be an expert in the do-calculus by any stretch. I’m writing this post partly to celebrate Pearl’s work, partly to tell you that it’s worthy of your attention if you haven’t come across it before, and partly to help me explain it to myself. To really grasp it I need to reread the whole book then start working through some trial examples; if I manage to get round to this while trying to close Hospify’s seed round (which is keeping me pretty busy), I’ll let you know.
In the meantime, do go and read “The Book of Why” for yourself. I promise you it’s worth it.