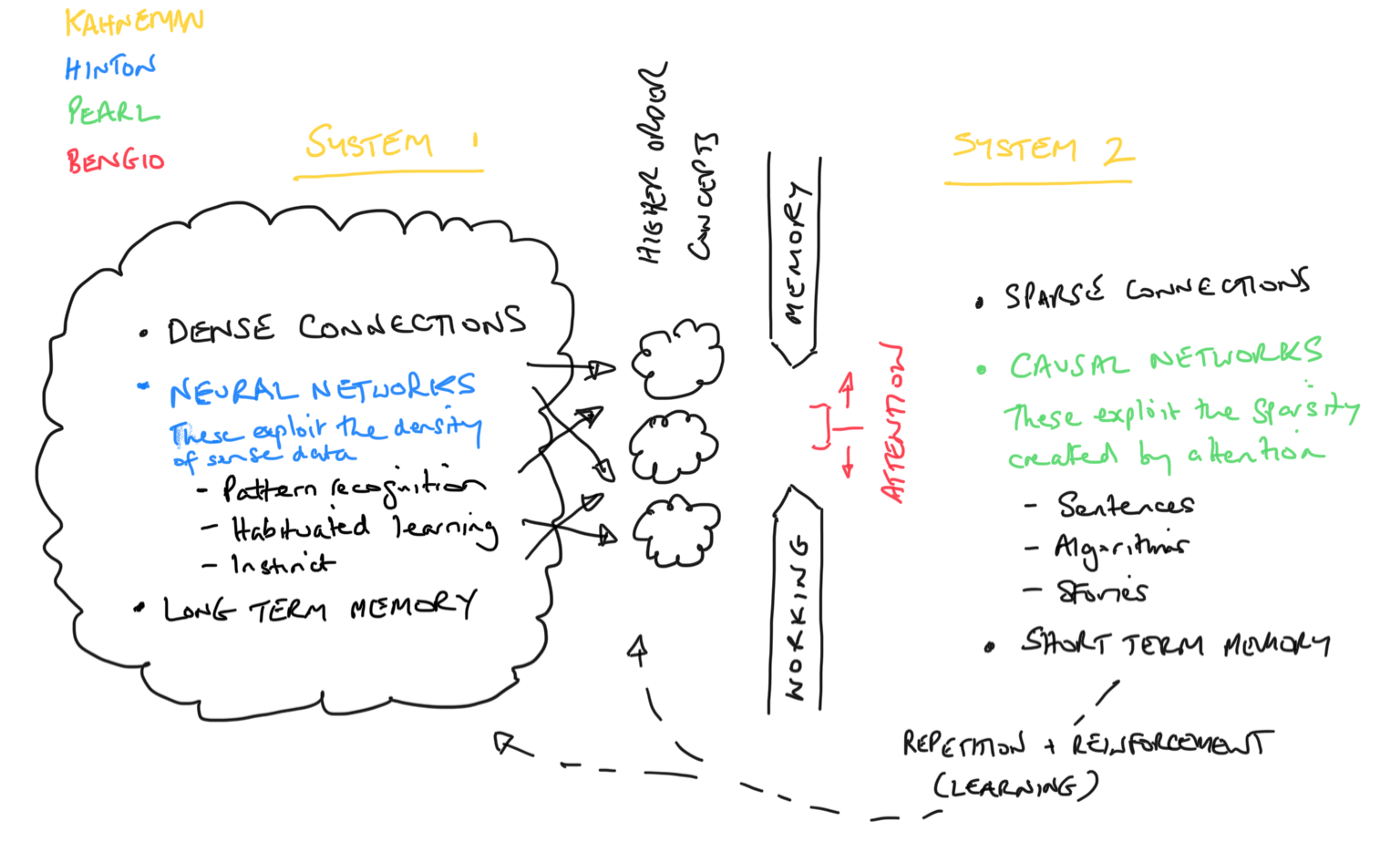
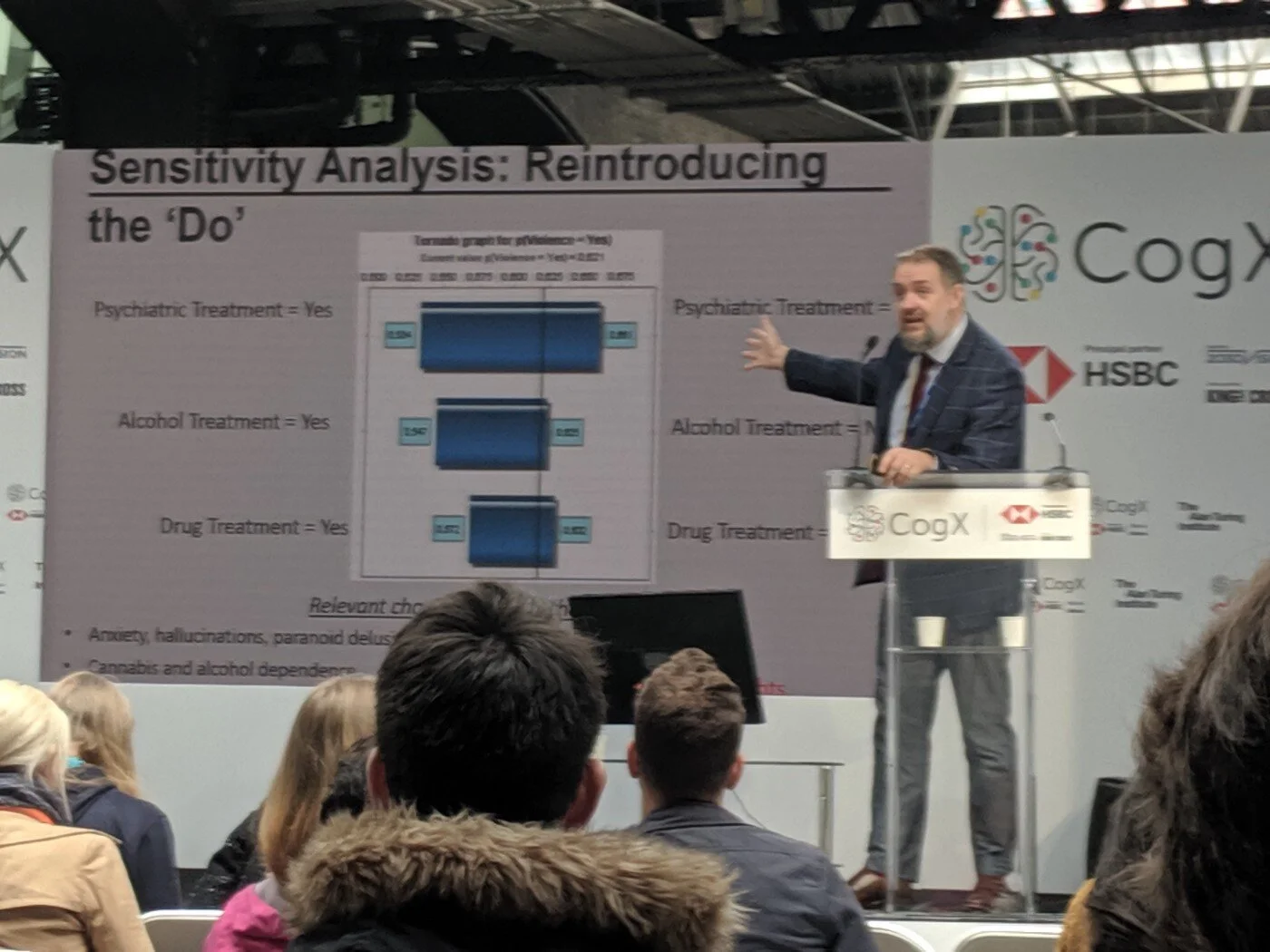
A review of “Exponential: How Accelerating Technology Is Leaving Us Behind and What to Do About It” by Azeem Azhar

Azeem Azhar’s “Exponential” starts out like many a techno-boosting tome: a smart, well-informed and optimistic account of current trends in and impacts of technology, a thesis about how we could better track this progress by using Wright’s Law than the more commonly used Moore’s Law, and a catchy concept - “that we’re living in the Exponential Age” - to hang it all off, perhaps in the hope of coining a term that will be deemed to have been definitive by posterity.
As the book progresses, however, it soon becomes apparent that there is more to Azhar than this first impression suggests. As consumers of his excellent weekly “Exponential View” newsletter (and its accompanying podcast) will know, Azhar is not your average tech evangelist. While he has extensive hands-on experience as both tech journalist and tech entrepreneur - and thus a deep command of his subject - he also has a deep concern for and interest in the real impact that all this tech is having on society. Democratic society, in particular.
He’s not afraid to say it, either. As early as Chapter 1 we find him castigating digital engineers for their culturally dominant view that “technology is neutral”. “Technologies are not just neutral tools to be applied (or misapplied) by their users,” Azhar insists. “They are artefacts built by people. And these people direct and design their inventions according to their own preferences [...] And that means that our technologies often recreate the systems of power the exist in the rest of society.” After several decades’ worth of Silicon Valley hubris this is a breath of fresh air.
Azhar proceeds to walk a neat line between indulging his admiration for and excitement about the incredible gains that technology is bringing and his awareness of its potential downsides and impact on the structures of power. He allows himself to be enthralled by the idea that “between these four key areas - computing, energy, biology and manufacturing - it is possible to make out the contours of a wholly new era of human society” while remaining continually alert to the very real possibility that such a new era could, if we are not proactive and careful, very easily turn out to be a place in which we wouldn’t want to live.
As the book goes on Azhar becomes increasingly critical of the monopolist behaviour of the current tech giants, the manner in which the homophily encouraged by social media is atomising our culture, the fact that AI systems can just as easily embody society's prejudices and offer new and insidious means of social control as they can transform business and science, and the way in which drone warfare is driving extreme asymmetries in military conflict.
All these points are made well and loudly elsewhere, for sure. But what’s so refreshing about “Exponential” is that Azhar makes them without losing his enthusiasm for the positive transformations that technology promises, and he uses them to develop a continued and determined case for governments and other social organisations to evolve policies and mechanisms of governance that are equal to the task that this new technological era presents. He even advances a case for more and more effective collective action by workers, a view that is guaranteed to raise hackles at Amazon, Google and Tesla, the point being that if we don’t haul our political structures out of the twentieth century and reform them to be equal to the challenge of controlling technology, it’s a pretty foregone conclusion already that technology and its overlords are going to control us.
Whether or not the era in which this battle rages will end up being known as “the exponential age” remains to be seen. What’s certain is that we need more writers and entrepreneurs of Azhar’s calibre around if we’re all going to share in its benefits.